This blog typically focuses on sharing observations from the twenty years I spent operating small-scale SaaS businesses. This post takes a different tack. It reflects more recent experiences, as I’ve transitioned over the past 18 months into the role of SaaS investor. That pivot has offered an exhilarating (and often humbling) opportunity to work with SaaS operators in a new way and from a different perspective. One of the things this experience has revealed is the need to be intentional about how investors and operators engage with each other. Failure to do so, I’ve learned, under-utilizes this potentially invaluable relationship and can lead to stale interactions. On the other hand, even a little bit of intentionality can drive more efficient and effective collaboration among company executives and board members / investors to the benefit of company performance. Below is a brief intro to the model we’ve adopted in recent months and how we’re using it to raise our game on this front.
We noticed that virtually all interactions between portfolio company executives and members of our investment team could be categorized based on two core questions. (1) Who is the owner / person responsible (portfolio company or investor) for leading a given activity or deliverable? (2) How much interaction does the exchange require? From these variables, an obvious 2x2 matrix emerged, as follows:
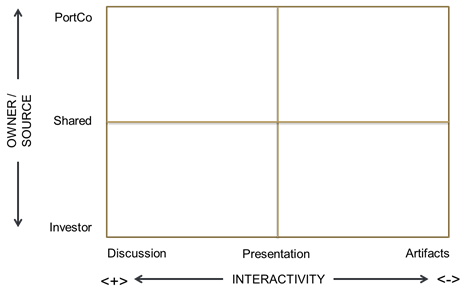
Because its useful shorthand to name quadrants of a 2x2 matrix, the following terms quickly attached themselves to each box.
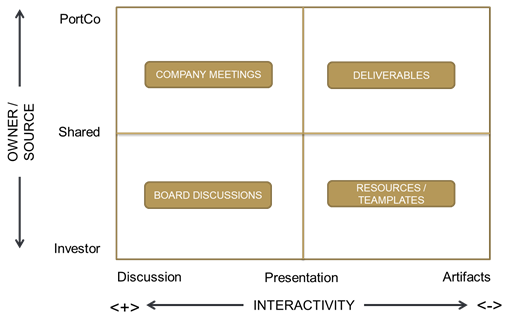
And just as quickly, we realized that this simple schema neither represented reality, nor provided a model that meaningfully improved our communications. But, with a few tweaks, it became valuable quickly. The trick was understanding that a binary notion of ownership makes perfect sense for artifacts or deliverables but makes less sense in connection to in-depth discussions about complex topics. To recognize this reality, the 2x2 morphed into something a bit more complex; and the following model came forward:
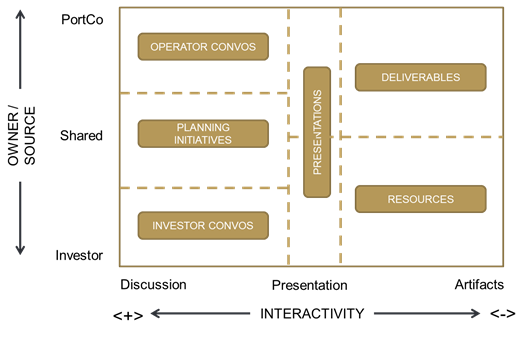
This was a game-changer for a few reasons. First, it became easy to plot virtually all our interactions / exchanges somewhere within this model. Below is a small example with just a few of the items on which our operators and investors / board members collaborate or exchange information:

Second, this framework established some shared language, through which we gained immediate communications efficiency. It became simple, when discussing an initiative or a deliverable, to identify the box it was believed to occupy…and to quickly uncover and address any areas of misalignment. When discussing a potential topic or project, it has become common for us to rely on shorthand such as, “I think this is a Box 4 topic, do you agree?” This has squeezed-out some previously existing room for confusion. To avoid all doubt, we use the following numbering system:
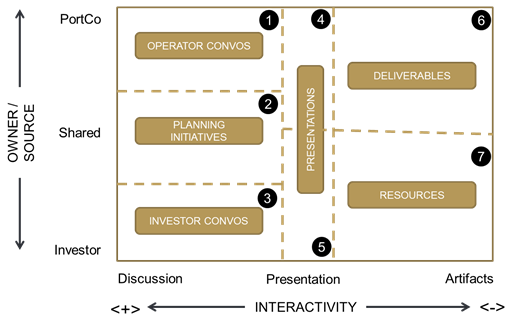
But the biggest benefit by far has been to raise our awareness of the amount of time and energy spent in each box…and our sensitivity to wasting time in the wrong box on a given topic. For example, in the first few months after an investment, we spend a good deal of time in collaborative discussion (Box 2: Shared Strategic Planning). That makes a ton of sense for many reasons, particularly during a period where there is a lot of shared learning around complex topics and where planning occurs through a collaborative and iterative process. But that can be really time consuming. And, as the company moves into more of an execution mode, it becomes advantageous to migrate operator-investor interactions more into boxes 4–7. When recently asked by a portfolio company CEO about a particularly thorny product-related issue, I reflexively suggested that we get in a room to discuss. Instead, he responded, “In this situation, it would be more valuable for me to hear a summary of your lessons learned on this topic, can we just make this a Box 5 presentation from you guys?” I was happy to comply; since we are all aligned around optimizing company performance. This kind of directive request helps us to arm operators with whatever support they need to succeed in the market.
This whole approach reminds me a bit of the balanced eating plate graphics that we learned about in Health class as kids. The general concept is timeless, even if the exact categories and proportions will forever be a subject to ongoing examination and debate.

In both scenarios, what’s most important is that there is (1) a healthy balance, (2) a framework for making good, intentional choices, and (3) a useful check against simply defaulting to the part of the plate — or the type of interaction — that satisfies our craving in a given moment. Finally, as the saying goes, variety is the spice of life. Our experience is that the same is true when it comes to interactions between operators and investors — a little planning and a bit of balance / diversity leads to more efficient and effective interactions that are also just generally easier for everyone to swallow.
It’s easy for leaders to get caught up in the day-to-day of running small-scale businesses. Particularly during challenging times, it can take all our energy just to “keep the wheels on the bus.” Unfortunately, a casualty of operating in this mode is that we tend to focus far less on the long-term composition of the team — who’s actually on the bus, whether they are in the right seats, and who should be getting on / off at upcoming stops. This is hardly surprising — such planning demands both discipline and foresight. It’s also difficult to get right: organizational design is quite complex, and according to research from McKinsey & Company, less than 25% of organizational redesigns succeed. With that in mind, this post can’t begin to scratch the surface on this rich topic. Rather, it simply introduces a quick-and-dirty exercise to help leaders elevate and think proactively about their organizational “bus” both now and in the future. What follows is a description of the exercise (the “What”), some tips around its execution (the “How”), and some observations about its effectiveness (the “Why”).
The What: The exercise is quite simple and builds upon something that virtually every organization already has available in some format — a current org chart. Using that as a starting point, the leader creates a series of hypothetical future org charts for the business. Specifically, (s)he creates four new / additional org charts, each representing successive six-month intervals into the future. This results in a total of five prospective org charts, essentially five snap-shots that look forward two years, six-month at a time. The five org charts are as follows:
The How: This really is a simple exercise, so there is no need to overthink it. But a few pro-tips can’t hurt; and the following will help make the exercise even easier and more impactful:
The Why: The primary benefit of this exercise is hopefully clear: it is a low-effort way for a leader to plan out with intention and purpose how an organization will grow over time. It works well because it doesn’t require any special skills, resources, or training; and it is something leaders can easily do on their own a couple times of year with a moderate amount of discipline in a short period of time. A few of the side-benefits, and why this exercise works in achieving them, are outlined below:
In closing, this exercise is largely about interdependency between the business outcomes and the people-related aspects of organizations. Leaders generally have a keen sense from a mission and financial perspective of where they want their businesses to be at various points in the future. What we tend to be less good at is identifying and aligning the roles and skillsets necessary to achieve those objectives. Yet, they are completely interdependent — the envisioned goals, and the difficult-to-define team / structure required reach them. This exercise aims to help navigate the organizational side of things. Hopefully, it can help leaders develop a far-seeing view of who should be “on the bus”…and provide everyone a much smoother ride toward the desired destination.
People say it all the time, usually with great pride: “We are a sales-led company.” Or, in businesses with deep technical roots, it might shape-shift into: “We’ll always be an engineering-led organization.” Marketing, finance, and product management can also feature in such statements. In fact, there are many versions of this claim by companies — and every one of them stinks. Here’s why; followed by a simple tool to help sidestep the alluring “we are led by X” pitfall.
In general, this whole way of thinking is wrong-headed for SaaS businesses, where organizational balance is key to sustainability. If one department or functional group within a company unilaterally leads, doesn’t that relegate all others to simply following the leader? Such an approach implies that those so-called secondary departments exist overwhelmingly in service to / support of that leading functional group. At best, this creates imbalance. Specifically, it sub-optimizes the potential of the whole organization, in favor of maximizing the output of one part of it. Worse, such thinking prioritizes pleasing internal “lead dogs” over the needs of important external stakeholders (e.g. customers, prospects, shareholders). This often results in unhealthy politics which eventually limit the growth and profit potential of the business. Regardless of which department we drop into this corporate Mad Lib, the outcome is consistently negative.
Beyond being a bad idea in general terms, “X-led” companies suffer unique downsides depending on which department occupies that leading role. Though the problems differ by department, they are highly consistent in how each appears from one company to the next:
Again, there are many variations of this same tune: Finance-led companies are fiscally responsible but can be brutally rigid workplaces. Even customer-led companies (as good as that sounds) often devolve into rampant incrementalism around customer feedback, risking eventual disruption by innovative market newcomers. Note: if forced to choose, I favor being a product-led company, as described by Marty Cagan in his excellent book, Inspired: How to Create Tech Products Customers Love. But even that can go wrong if implemented in a narrowly literal way (more on that in another post).
If any of these types sound familiar, you are not alone. To some degree this problem will always ebb and flow in organizations that are every bit like constantly evolving organisms. This makes it quite difficult to tackle this problem in its totality, without first mustering a ton of organizational will. Instead, one simple practice can improve life for all within any X-led company: rethink when each department engages with the others. Here’s how:
In an X-led organization, one department tends to act; and all other downstream departments are later forced to react. Of the many problems this creates, a big one relates to timing — when one department leads, all others are usually late to the game. For example, a company’s Client Success team will always struggle to delight the customer if they only learn after-the fact what commitments a salesperson has made in the sales cycle. Similarly, salespeople cannot credibly convey the company’s product vision to prospects, if they are only informed of the product roadmap as new features are being released. In both cases (and countless others in companies everywhere), the problem relates to WHEN one department is engaged by others. Two questions to ask in virtually every one of these situations are:
If this sounds simple, it is. But it is also effective. These seemingly simplistic questions never cease to foster a rich and wide-ranging discussion. They also inevitably reveal opportunities to move cross-department collaboration earlier in the value-chain, which yields demonstrable benefits. These include: informing more successful client implementations, surfacing development issues in a more timely / manageable manner, and driving more holistic support and activation of Marketing initiatives.
One last pro-tip for getting your money’s worth from such an exercise — invite every department to the party. Just as it is sub-optimal to have a company that is led by a single department, this exercise also suffers when it is undertaken by only one (or two) departments. Instead, it should be all-inclusive. When every department needs to answer these questions for each of its peers, it won’t be long before everyone leads…and everyone follows.
There’s some debate about who first said, “Never waste the opportunity offered by a good crisis.” (N. Machiavelli, W. Churchill, R. Emmanuel). Whatever its origin, its meaning is clear: turbulent times lower collective resistance to change and provide a rare opportunity to challenge conventional wisdom. Unsurprisingly, this quote seems to have resurfaced frequently during these recent chaotic weeks; and its sentiment deserves some focused attention as it relates to small-scale software companies.
First things first: it’s hard to think of any crises that are actually “good.” The current COVID-19 pandemic is heartbreakingly awful in countless ways; and this post will not debate that. Neither will it focus on the specifics of the current crisis. Rather, this post is intended to support leaders looking to optimize this moment to bring both stability and positive change to their organizations…and to avoid mistakes that can make a bad situation worse. It does so by building on John Kotter’s 8 Step Process for Leading Change to help ensure that change initiatives are beneficial, successful and long-lasting.
What follows is the officially published “hook” and high-level summary for each of Kotter’s 8 steps for leading change, along with some brief situation-specific commentary from me. Please note: Any text in BOLD ITALICS is the exclusive work of John Kotter and the Kotter organization.
Amid the current crisis, Kotter’s steps for leading change appear as timeless and universally applicable as ever. And they seem particularly valuable for small-scale software businesses, given the existential threats start-ups face and the lightening-quick rate of change in their operating environment. In the midst of the current pandemic / economic crossfire, these steps offer some structure and security for those leaders looking to implement positive change and “make the most” of a decidedly challenging crisis.
In the 1992 legal drama film “A Few Good Men,” Colonel Nathan Jessep (Jack Nicholson) barks an iconic and scathing reproach to Lieutenant Daniel Kaffee (Tom Cruise) and to the world at large, “You can’t handle the truth!”
While this made for an epic movie moment, Colonel Jessep got it wrong when it comes to team members in small-scale software businesses — they can, indeed, handle the truth. Actually, they require it. Highly intelligent and resourceful knowledge workers don’t need a ton from their leaders; but there is a short list of critically important must-haves, particularly in times of crisis. Specifically, they need to know these few things about company leaders:
Like many people, I’ve spent a lot of time in recent weeks trying to get a handle on things by understanding what others are seeing and hearing. As a result, I’ve had the opportunity to speak with many company leaders about what they are experiencing and the nature of communications within their own teams. Particularly interesting to me is how they are choosing to address the harsh and uncertain reality of today’s business climate.
What I observed is that many leaders whom I deeply respect are being quite transparent regarding the challenges their companies face, and about the various options for navigating those challenges. A number of those same leaders expressed pleasant surprise at having received positive feedback following particularly hard-hitting messages to their teams. Intrigued, I researched further and was able to review and compare in varying levels of detail how a number of leaders have been communicating with their teams of late. What emerged from that informal study was a wide range of styles, but also a highly consistent set of practices employed by experienced and effective leaders. These include:
In sum, small-scale SaaS company teams want a few core behaviors from their leaders; and those don’t include babysitting or happy talk. Quite simply, they want the substantive and relevant truth. But neither do teams desire information overload. They don’t need every little shred of information that impacts the company either positively or negatively on a minute-by-minute basis. They should not be subjected to the turbulence and air-sickness which comes from experiencing first-hand every rise and fall in altitude as the company flies along. That’s a different Tom Cruise movie altogether.

The number one reason startups die is that they run out of cash. This is well known; and plenty of resources currently offer excellent advice for surviving turbulent times. But this is scary stuff with existential consequences for small-scale businesses; and guidance around cash-preservation can be overwhelming for company leaders. Having experienced challenging environments in 2001 and (even more so) 2008, I remember making the mistake of being trapped for days in forecast models or repeatedly scouring a laundry-list of line-items to be considered for cost-cutting. I was mired in the tactical weeds and later came to appreciate that some broader perspective would have helped guide my approach. The purpose of this post is to share a few lessons learned on this front and to offer some high-level frameworks to inform the thought process behind cash-conservation efforts.
I. Secondary Goals / Sacred Cows: Leaders intuitively understand the goal of cash-retention initiatives — to survive. It’s quite simple; just don’t run out of cash. But it is never that simple; and that is why it’s helpful for leadership teams to clearly set secondary goals for any expense-management initiative. This approach answers the question, “what is the NEXT most important objective of this effort (beyond simply staying solvent)?” For some companies, that may be safeguarding the customer experience and brand loyalty. For others, it could be maintaining the engagement / continuity of the entire team or retaining top talent. For more mature businesses, it might mean ensuring the business is positioned optimally for whenever the economy eventually turns around. Another way to arrive at similar clarity is by identifying “sacred cows” — those parts of the business where compromises will never be made. Whichever route is taken, this exercise helps leaders keep one eye — even in a crisis moment — on what is important for the longer-term health of the business.
II. If / Then / Then-by-When: The purpose of this mnemonic is to help leaders rise above the detail of expense-management and think beyond the tyranny of spreadsheets. It forces execs to go through a three-step business planning process, as follows:
In sum, this framework forces structure in what can otherwise become an ad hoc reaction to environmental challenges. It demands that company leaders a) thoughtfully envision potential scenarios, b) identify the qualitative and quantitative impact of those environmental forces on their business, and c) codify the steps and related timelines needed to address the challenge faced.
III. Assumptions, Decisions, and Control: Re-forecasts are inherently unsettling; and it can be difficult to know where to begin. One way to get a foothold is to separate where to make “assumptions” and where to make “decisions.” A general rule of thumb is to make assumptions about the top-line (sales / bookings and corresponding revenue) and make decisions around expense management. Why?
The truth is that companies ultimately cannot control whether clients actually buy from them; so, they need to make educated assumptions about customers’ buying behavior. Further, we’ve found it helpful to first focus on (and make the most pessimistic assumptions about) the types of revenues that companies least control. This generally means new sales to new customers, since they are the most speculative and rely most on customers making a proactive and incremental outlay of cash. Then, we move methodically down the risk ladder. The next most at-risk revenue class tends to be expansion sales to existing customers. Then come usage-related revenues. Finally, existing client renewals tend to be the most secure (but still ultimately at-risk!). When companies have great data, they can even further refine their renewal assumptions based on cohorts (products used, type or size of customer, and date of initial purchase). Breaking revenue streams out in this way allows companies to thoughtfully and granularly quantify risk to the top-line.
When (and only when) a company updates its top-line expectations, they can then begin to make informed decisions about expense-management — because they ultimately control expenses and can manage them accordingly. It’s helpful to sequence expense related decision-making opposite to that on the revenue side. Start with the expenses over which the company has the MOST near-term control and work the other way. This is because controllable costs offer the best ability to quickly aid in cash conservation. Highly controllable costs are almost always discretionary / un-committed, non-personnel expenses (e.g. marketing campaigns). Month-by-month subscriptions tend to come next. Consultants and contractors are also somewhat manageable (albeit not nearly as easy to pare back). Drastic measures such as “reductions in force” are far trickier still; and long-term leases (e.g. rent and pre-paid annual contracts) are often most challenging to derive savings from in the short-term. The following graphic from an excellent recent study by A&M (Alvarez and Marsal) concisely captures these dynamics and expands well-beyond.
A note about the elephant in the room: By far the most excruciating expense-related decisions revolve around personnel costs of the core team. Unfortunately, this is also the richest vein to mine from an expense management standpoint, because the majority of expenses in SaaS businesses are people related (yet again proving the adage that nothing valuable is ever easy). Moreover, the dynamics of personnel decisions are deeply complex and interdependent both financially and culturally; and leaders need to make choices in this area with the utmost consideration and care. This topic certainly warrants a more complete discussion but is not the focus of this particular post.
Okay, so…with these frameworks in the toolbox…what comes next? As is often the case when it comes to operational execution, it starts with communication. A range of diverse stakeholders will be involved in, and impacted by, any of the activities described above; so clear, effective communication is key. Although these decisions are made based on data and reason, their communication demands empathy and compassion — none of us wants to be the leader who gets stuck in spreadsheets(!). In a world where working at a physical distance is not just a choice, but a necessary health condition, such compassionate communications are more important ever.
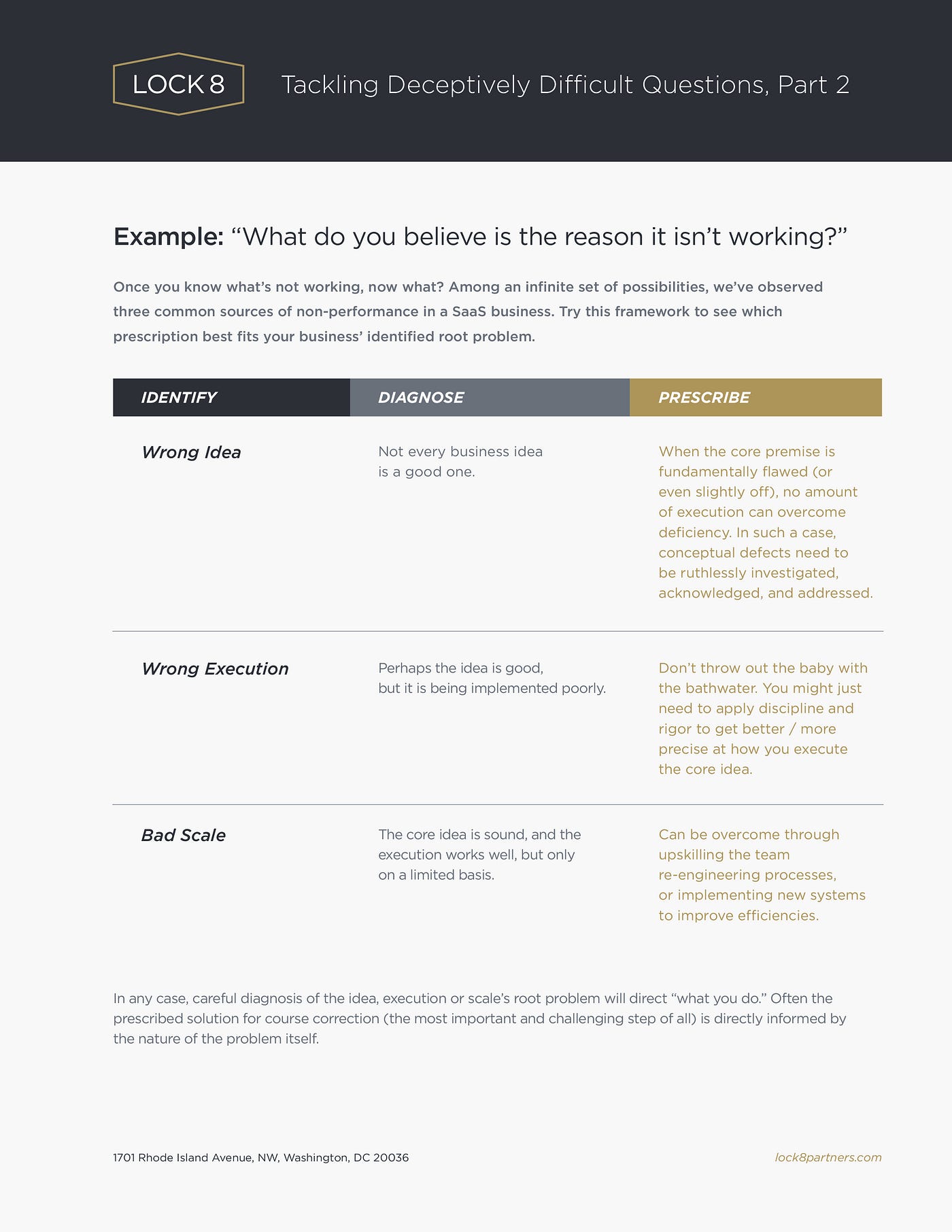
This blog recently featured a post that invoked the First Rule of Holes (“Stop Digging!”). That piece had been triggered by some business-planning discussions; and it advocated taking a structured approach when tackling deceptively difficult business questions. In that case, the seemingly innocuous question was “What do you do when it’s not working?” That post offered a framework to assist in the first step of problem-solving — actually identifying the existence of a problem in the first place.
This is part two of that post. It picks up where the last one left off: developing hypotheses to test why something isn’t working. Building on the initial framework, this piece endeavors to share a structure to use in the critical step of diagnosing the source of a business problem.
When I joined my first subscription-based software business in 1999, the term Software-as-a-Service wasn’t even a thing. Since then, SaaS has emerged as the dominant form of software delivery, accompanied by quantum leaps in the study and understanding of its underlying business model. Correspondingly, there is a wealth of outstanding available resources that explain the fundamental principles and performance indicators used to evaluate and operate SaaS businesses (including this and this and this, to name only a few). These and countless other sites are invaluable in explaining the metrics that matter in SaaS. But there is an important metric that seems to consistently fly below the radar. While it likely has many names, we call it DROP ALLOWANCE. Drop allowance takes an opaque retention target and brings it to life by applying it to the actual pool of renewing client logos and revenue. The purpose of this post is to examine the concept of drop allowance and to explore some related metrics and their use.
First things first: drop allowance is focused on GROSS CHURN. For good reasons, the SaaS world seems to have increasingly focused in recent years on NET CHURN and the related NET REVENUE RETENTION. While those KPIs can be quite useful, I’d argue GROSS CHURN (and the inversely correlated GROSS RETENTION) is unique in its ability to spotlight and quantify the underlying stickiness of a software solution. Whereas successful upselling can boost NET REVENUE RETENTION and camouflage troubling subscription-drops, there is simply no hiding drops and down-sells with GROSS CHURN. And, although virtually all SaaS businesses set targets for some flavor of churn/retention, seemingly fewer monitor gross churn against an actual drop allowance pool.
Another point of set-up: the core value of a drop allowance is to translate high-level retention targets into something meaningful and actionable for operators of the business. Churn/retention targets tend to take the form of high-level percentages (e.g. “…our goal is 5% gross churn,” OR ”…we’re planning for 95% gross retention”). The problem is that such percentages tend not to be very meaningful on a day-to-day basis to front-line people responsible for ensuring client renewals. To combat that, drop allowance can be easily calculated, as follows:
Hopefully, this is all straightforward, so let’s dig into an example of a business with the following profile:

We’ve found that this small act of translating percentage-based objectives into a $-based goal to be helpful to the whole team, and particularly to renewal professionals (such as Client Success Reps, Account Managers, and Salespeople). But that’s just a start. Next, layer in ACV, as follows:

This simple math makes it clear that if we head into the year with 300 paying clients, achieving our retention goal relies on having no more than 15 average-sized cancel their subscriptions across the course of the year. Gulp — this just got real.
Of course, we have large clients and small clients; and this approach also helps quantify the clear-and-present danger of large drops to our company’s health. Although I tend to err on the side of believing every client is worth working to retain, this also raises awareness among the team around where to direct their finite retention-focused resources.
By quantifying the total number of budgeted dropped logos, this also offers an approximation of the acceptable rate of drops across the year. If this business has ZERO seasonality (and hence, no renewal concentration in any given quarter or month), it can theoretically afford to average 1.25 logo drops per month [15 Average Logo Drops Allowed / 12 months]. But we can be even more precise than that, and this is where the real value of metrics related to drop allowance emerges. For the sake of argument, let’s proceed with that simplifying assumption that there is zero seasonality in the business; and that all 300 of the existing clients had been sold evenly across all historical months. We could plot out the renewal pool ($1.5M across 300 clients), drop allowance ($75,000 across 15 logos), and a related monthly budget for each, as follows:

Then we can make it more useful and dynamic by showing these numbers as cumulative across the year, as follows (with shading to help readability). It would look like this:

So far, so good, right? Now…let’s move out of the realm of plans and averages, and into the messiness of the real world.
Let’s assume for a minute that we’re through five months of 2020, and we’ve been actively managing and monitoring our renewals, and they look like this:

Viewed through this lens, it’s clear that retention has significantly worsened after having started the year well. But without a baseline, it’s hard to deduce much beyond that general assessment; and it’s even harder to quantify when we factor in complexities such as down-sells, seasonality of renewals, and widely variable client-sizes. Instead, leveraging drop allowance can offer a granular budget-versus-actual look every month (or even more real-time) and on a cumulative basis, as follows:

This is where the real pay-off comes. Armed with the above information, we can boil all of this renewal complexity down to one single metric that will tell us how we are performing on renewals, not just against the (maddeningly distant and monolithic) year-end goal, but rather on a rolling basis and relative to the seasonality of our renewal pool. This can be done by establishing a ratio of the RENEWAL POOL COMPLETE (“RPC”) [A] / CUMULATIVE DROP ALLOWANCE USED (“CDAU”) [B]. Using the numbers from above, it looks like this:

Admittedly, that is an awful lot of words, so we like to simply call this the YEAR-TO-DATE RETENTION RATIO. Whatever it’s called, this KPI offers easy-to-understand clarity around gross retention. By looking at this one number, we can know where we stand, relative to what renewals have already come due and which are still outstanding throughout the year. Quite simply, a YTD retention ratio >1.0 means that we are outperforming relative to possible renewals year-to-date; and a ratio below 1.0 should be cause for concern (i.e. we’ve already used up more of the drop allowance than budgeted, relative to renewals past due). Because I’m a visual learner, I like to see all of the above numbers as charts; below is a simple one for the YTD RETENTION RATIO from this example.
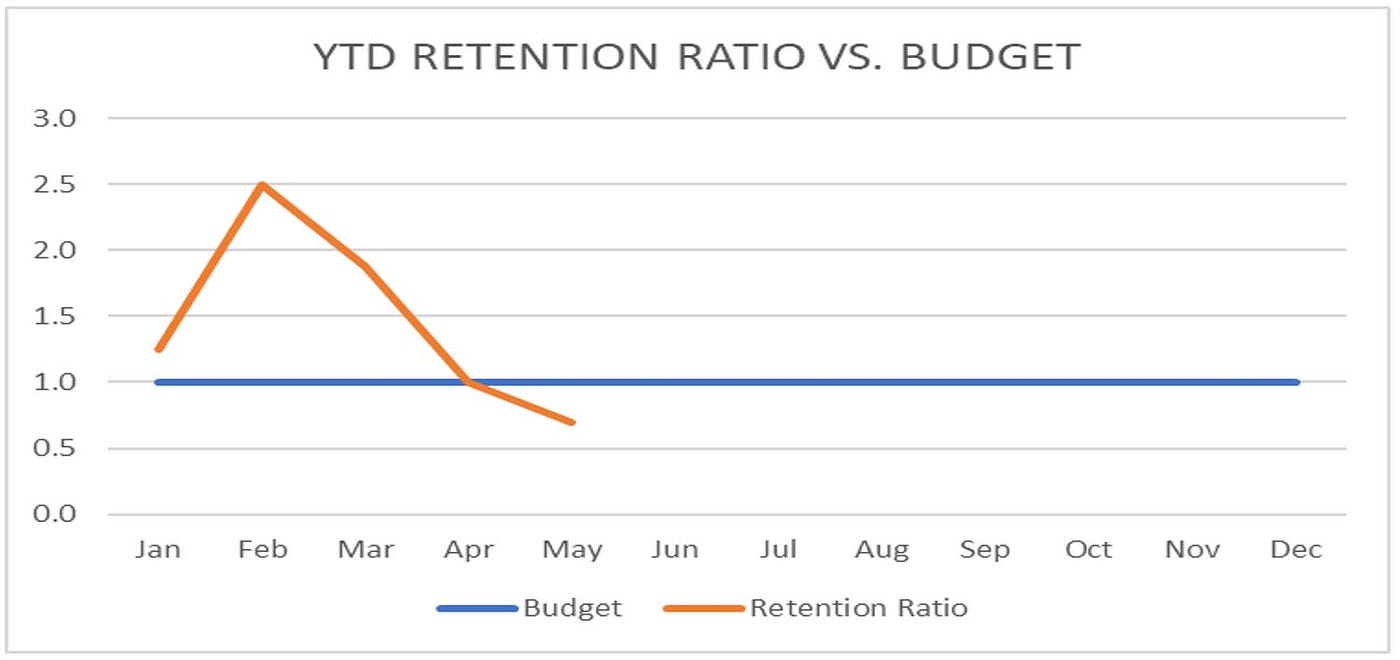
This chart helps highlight how YTD retention ratio can serve as an early warning system, signaling the need for intervention. More so than most metrics, it spotlights changes in churn patterns with speed and sensitivity, which can tip-off operators to dig into any number of related variables and levers. Taken together, these can that help inform a number of operating decisions, including: timely personnel changes (e.g. does this problem warrant hiring an AM dedicated to renewals?), systems investments (should be invest in client engagement solution?), and process improvements (e.g. how can we enhance our on-boarding?). I’ll plan to dig into this aspect of things in a future post.
Closing: I know that was a lot of math above, so let’s conclude with a few closing comments.
The “law of holes” was drilled into my head as a kid; and it is sound advice. The problem, of course, is proactively identifying whether and when you are actually digging yourself a hole.
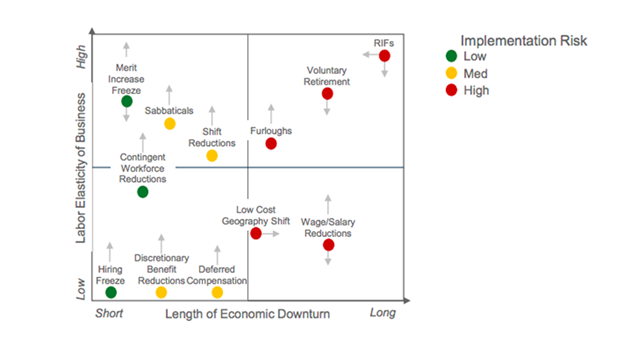
I was recently reminded of this dynamic while visiting with the impressive leadership team of a 40-ish person SaaS company. We had met to discuss a range of topics relating to the life cycles of growing businesses. One person posed a seemingly straightforward question to the group that resulted in an immediate and spirited exchange: “What do you do when it’s not working?”
As a rich discussion unfolded, I remained silently stuck in the subtle, complexities of the question. While the debate whizzed past, I did what I often do when stranded in such situations — start to draw. The graphic below is a more formalized version of my notes and thought process from that session. It’s also an attempt to offer a simple approach to tackling this deceptively tricky question, and potentially others like it that prove surprisingly elusive to wrangle.

In a previous post, I shared observations relating to the process of re-platforming a SaaS solution. I was grateful when a former colleague reached out to comment on that piece. He offered that the term “SaaS” was somewhat limiting in this case, and that the principles in the post applied to any number of modern software delivery models. And, because no good deed goes unpunished, I asked him to guest-write an article that topic. Thankfully, he agreed! Chad Massie is highly qualified to opine on the issues encountered when deciding how to utilize cloud services while modernizing the architecture of a SaaS solution. I’m delighted to share his thoughts on this topic on Made Not Found. Thank you, Chad for the post that follows.
____________________________________________________________
For any business, but especially for those providing software as a service, cloud infrastructure offers a tremendous opportunity to drive organizational value. The question is not if a cloud strategy is appropriate, but rather which strategy to pursue and how to ensure that business and user value drive the decision-making. The five observations below were developed over five years of operating a high volume, high availability, cloud native software platform, and though there are several technical take-aways, the most important lessons are the human ones. Those observations and the related reflections on people and teams are below:
There is no single cloud strategy
In ways that can be both advantageous but also challenging, not every software or business will be best served by the same cloud strategy. This provides great flexibility in terms of timing and investment, but it also signifies that time spent up front posing the essential questions, understanding the needs and clearly defining the desired goals, and establishing the acceptable risk profile will pay considerable dividends (e.g., start with why).
The primary question of whether to “rehost” or “replatform” or “rearchitect” has no obvious answer. Each of these approaches has pros and cons — from a technical perspective, of course, but just as importantly from cultural, operational, and business value angles — and all can offer benefits for your organization. A rehosting strategy can help reduce near-term risk but might slow the upside value for an aging application; rearchitecture can provide a path for addressing major technical debt and modernizing the user experience but brings with it more significant complexity and change that may be more than your business or team is in a position to accommodate. Again, understanding your own context and priorities will help lead you to a better decision for your organization. You might determine that experimenting with an application that has a lower risk profile (e.g., an internal application, a non-mission critical platform) or a specific operation (e.g., disaster recovery) is the path that will ensure long term success, or you might determine that an all-in approach is the way to best serve your customers and inspire your staff.
Cloud is a culture (change)
Processes, organizational structure, and technical strategies that were foundational to success in an on-prem or hosted SaaS operation will not necessarily translate in a true cloud environment. The cloud requires a shift in cultural thinking, and as a result, demands a well-considered change management strategy for your team(s). One common theme is establishing a Devops mindset whereby the members of your various technical teams are involved in the full lifecycle of product delivery and support. Another is fostering an environment of knowledge-sharing and a blamefree ethos. The amount of new learning to be performed and the pace of change in cloud technologies require open communication, collaborative work, and “failing forward.” Further, the culture of learning and partnership requisite to success in the cloud extends beyond technical roles; product, marketing, finance, support, and management positions will all see implications to their work and their team interactions as a result of a cloud-oriented strategy. They must be incorporated into the transition planning and energized by the opportunities every bit as much as the technologists.
Patterns are your friend
Similar to the way software and user experience patterns have emerged over time, there exist many proven cloud architecture and process patterns that can help reduce effort and risk while ensuring security and operational reliability at scale. Whether incorporating elements of Amazon’s well architected framework, pillars of great Azure architecture, or Google’s cloud adoption framework — or something else — make use of these cloud patterns to shorten the time it takes to realize benefit for your organization. As with anything in life, though, an extreme position can limit our perspective, and cloud architecture is no different; it is both a science and an art. The scientific patterns and frameworks should be used to help streamline your architectural approach, but their parameters shouldn’t get in the way of your team’s creativity, the practice of experimentation, and applying their unique contextual knowledge in crafting the most valuable solutions for your business.
Instrument, monitor, and automate
Cloud infrastructure and the technologies that have been developed to support cloud-based software lend themselves extremely well to measurement and instrumentation. The fidelity of this information provides exceptional insight into the operations of your technical platform, in identifying issues proactively, and in understanding user behavior. Additionally, since utilization of a cloud infrastructure eliminates the dependence on physical hardware and enables access to on-demand scale, your strategy should push to automate as much as possible. Besides reducing repetitive efforts, automation will diminish the risk of human error and security exposure, increase overall quality, and help in delivering an optimal experience to your end consumers.
The cloud is constant innovation and reinvention
Advancing a cloud infrastructure strategy is an amazingly exciting journey. The dynamic nature of the landscape forces evolution and thoughtful change. As with any sound technology strategy, it demands attention to maintenance, performance, and reliability, but it also provides for reinvention and innovation in manners that did not exist previously, especially for small and medium sized software businesses. Rather than investing large amounts in original R&D, you could choose to utilize your cloud vendor/partner as your R&D arm, investing your resources in making the most of the innovative assets they bring to market while also providing enormous professional growth opportunities to your team. A cloud architecture gives you much more flexibility and a broader range of strategic options than has been historically available to SaaS companies, allowing you to select an approach that best meets the needs of your business, your team, and your customers.
Though the pathways toward a cloud architecture are now much more well-worn than they were several years ago, each software platform and each business is different. Coupled with the reality that cloud technology is a perpetually changing environment, there are no universal strategic approaches that will guarantee success. However, if you start with the right questions and understanding of the business drivers, build a work and communication plan aligned around strategic goals, and advance a team culture that values learning and collaboration, I believe the lessons above are applicable globally and can help ensure that your organization reaps a cloud strategy’s tremendous benefits.


